This is a followup to my last post, Making Bitcoin Fast: Introduction. This post is going to explain some background about what UTXOs are and what the chainstate database is used for.
Originally I planned to include information about how UTXO data is actually encoded in LevelDB, but to keep this post at a manageable length I'm saving that for the next post. Experienced Bitcoiners will already be familiar with most of the content here, so this is more targeted at people who don't understand the UTXO model or what the chainstate database is used for. The next post will be more technical (and is mostly written already).
The Chainstate Database
Bitcoin is a trustless, distributed digital currency. To operate a Bitcoin node you need to be able to do the basic accounting task of validating new transactions you see on the network. This means you need to be how much money everyone has, and who actually has the money. The fact that there's 170 GB of historical data in Bitcoin's blockchain is totally irrelevant for accounting.
Let's say Alice has 1 BTC and Bob has 0 BTC. Alice creates a transaction that sends her money to Bob. After receiving the payment Bob sends it back to Alice. They do this 100 times, and at the end Alice ends up with 1 BTC (minus whatever was lost due to transaction fees) and Bob has 0 BTC. If you're operating a node right now, you don't really care about those 100 transactions. You need to validate and track these transactions as they occur. But at the end, all you care about is the final state of the system.
The information about how much money everyone has right now is called the chainstate database. I call it the "chainstate" database because that's literally the name of the directory that Bitcoin creates. This is also called the UTXO set. You can think of the chainstate database as the information that's actually critical for doing accounting tasks. It does not contain old historical data. It only contains information about balances that matter right now.
Understanding this is critical to understanding why Bitcoin has any chance of scaling at all. Right now the Bitcoin blockchain is about 170 GB. That's a lot of data, but only a small fraction of that is data is unneeded when operating a Bitcoin node. The chainstate database is about 3 GB in size. That's a pretty modest number all things considered. You could fit the chainstate database on a typical flash drive or phone. This series of posts is going to be about this database. The right way to think about this is the database that stores the relatively small amount of data that's actually required to do the accounting tasks required when running a node.
If you have a full Bitcoin node running you can check the size of your copy of this database using the following command:
# This commands lists the size of the chainstate database.
$ du -sh ~/.bitcoin/chainstate
2.9G /home/evan/.bitcoin/chainstate
The exact number you'll see might be a little bigger or smaller than this due to some implementation details about how LevelDB works, but the number you see shouldn't be too much larger than what I've shown here.
UTXOs And Bitcoin's Accounting Model
In the last section I explained that the chainstate database stores accounting information about active balances in the Bitcoin. I also noted that this is called the "UTXO set". In this section I will explain more about what UTXOs are, and the basic accounting model used by Bitcoin.
The Accounts Model
Consider for a moment how accounting for a standard bank checking account works. If you have a checking account you have an account and routing number that identify your account. Your bank uses these two numbers to track the balance in your checking account. When you cash a check that balance goes up, and when you make a payment that balance goes down. This is called the "accounts" model, and for many people it's the natural way of thinking about tracking payments and balances. It's an accounts model because balances are associated with accounts. This is model is used by most other monetary instruments provided by a traditional bank. For instance, debit cards and credit cards have a 16 digit number on them that identifies which account the card is associated with.
You could build a cryptocurrency with this kind of accounting model. The way you would do this would be to have everyone generate a private/public key pair. The public key would act like an account number. This is essentially how Ethereum and most other cryptocurrencies work. However, this kind of model has a number of flaws.
To start with, it's not very private or anonymous. Anyone can anonymously create an account by generating private/public key pair without revealing their real world identity. But this anonymity goes out the window as soon as you actually have to transact with someone. For instance, if you want to split the bill after getting dinner with friends you need to get you their account numbers (or "addresses"). Once you know this you can figure out exactly how much money your friends have. This is kind of weird, and not information most people want to reveal to everyone they interact with.
There's another flaw of the accounts model though that's not as well understood. In a lot of ways I think this second flaw is more interesting, and perhaps a more serious problem. The problem is related to making sure balances cannot go below zero, which I'll explain here using an analogy related to making an online purchase with a traditional debit card.
Suppose I have a VISA debit card and my balance is $100. I go to two online sites, and try to make $90 purchases on both of them at the exact same time (e.g. I had the "Buy" button ready to go in two browser tabs). The expectation is that one of the payments will go through and the other will be rejected. They definitely should not both be accepted. This works because a central computer on the VISA network picks an ordering for the transactions. It decides that transaction A was first and transaction B was second. It sees transaction A as spending available funds and then debits funds from the account. Then it sees B as overdrafting, and rejects the transaction. When the transactions happen simultaneously it doesn't matter which transaction is selected as the first transaction. All that matters is that some ordering is chosen and enforced.
This is central to the accounts models: all of the transactions made by an account need to have a strict sequential ordering applied to them. This is the only way to ensure that account balances never goes below zero. How do you actually do that in a distributed system though? It's easy for VISA to do because they can route all of the transactions for an account to a central computer that enforces an ordering. It's not so easy in a distributed peer to peer system that doesn't have a central authority. There are ways to do it, but they're complicated and have some serious drawbacks, particularly when considering maximum transaction throughput, particularly when considering maximum transaction throughput.
The UTXO Accounting Model
Bitcoin does not use an accounts model. Bitcoin uses a novel "unspent transaction output" (or UTXO) model. Compared to an accounts model, the UTXO model provides improved privacy, and also elegantly solves the problem of making sure balances can't go below zero in a distributed system. The way this works is a little strange if you haven't encountered it before, so don't worry if this doesn't make sense the first read through.
I think the easiest way to explain this is to start with how new coins are created. The job of miners is to find a new block to append to the blockchain. They look at pending transactions and come up with a valid block containing some of these transactions. This done using a system called "proof of work", which ensure that blocks are found in a fair distributed manner, without relying on traditional synchronization mechanisms. Each block has a list of transactions. There's a special transaction in each block called the coinbase transaction. This transaction creates a brand new coin owned by the miner. Currently the block reward is 12.5 BTC, which is the inflation amount of new coins created in each block.
Let's say Alice is a miner who recently mined a new block. At this point she has a coin worth 12.5 BTC. Alice wants to send Bob 4 BTC. She creates a transaction that has two outputs (which roughly correspond to Bitcoin payment addresses). The first output is for 4 BTC and goes to an address Bob provides her. For the second output Alice creates a public/private key pair, and sends the public key 8.5 BTC of change. In this process we started with one coin worth 12.5 BTC and ended up with two coins worth smaller amounts. The original 12.5 BTC coin is considered to be spent, and the two new coins are unspent. These two new coins are "unspent transaction outputs", or UTXOs.
As we saw coins can be split as the result of a transaction, where one coins becomes two. The opposite situation happens when making a high value payment from a number of lower value coins. For example, let's say Bob already had coins worth 1 and 2 BTC respectively. At this point he has a total of 7 BTC spread across three different coins (1 + 2 + 4). If he wants so send Carol 6.5 BTC he would create a transaction that uses all three of his coins as inputs. The transaction sends 5.5 BTC to an address given to him by Carol, and 0.5 BTC back to a new change address he generates. In this example the transaction turned three UTXOs into two UTXOs. In general a transactions have one or more inputs and one or more outputs, and a transaction can increase or decrease the total number of UTXOs.
The reason this simplifies the accounting model is that we don't need to sequence transactions in the same way as an accounts model. Coins are in a binary state, spent or unspent. Since coins can only be spent once, we only need to track unspent coins. This also helps during periods of network congestion because it makes it possible for wallets to create transactions that are independent from one another. This independence of transactions prevents a low fee transaction from blocking a high fee transaction. This system isn't strictly simpler, as some other things become more complicated when using UTXOs. But from an accounting point of view the system is simple and easy to reason about.
By the way, these UTXOs are quite literally called "coins" in the Bitcoin source code. A coin does not have to have a unitary monetary value, which makes the term a little confusing. For that reason I generally prefer to call them UTXOs.
UTXO Age Distribution
Every UTXO is created in some block. We can consider the age of a UTXO to be the age of the block that first included it. I was interested in learning more about the age distribution of UTXOs, so I wrote some code to dump my local UTXO set and generated some graphs and statistics.
Since a UTXO can only be spent once, my expectation was that most UTXOs would relatively young, i.e. there would be a lot more recently created UTXOs than old UTXOs. The actual results were somewhat surprising to me. In the graph below the blue line shows the proportion density of UTXOs in each bin, and the red line shows the cumulative proportion of UTXOs age over time.
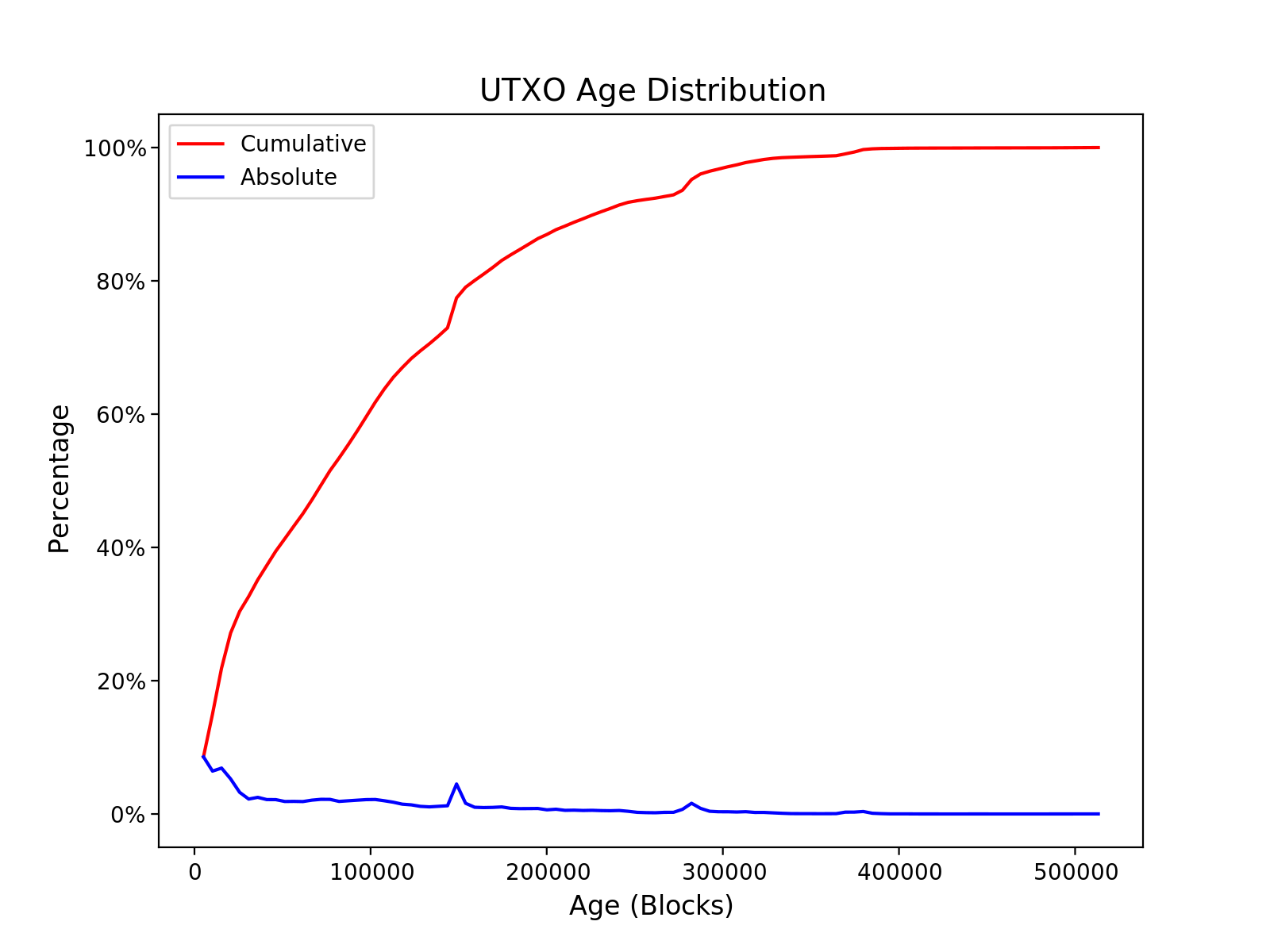
As you can see from this data, there is a bias towards young UTXOs, but the bias is really not that extreme. About 50% of the UTXOs have an age of 100k blocks or less. At 10 minutes per block, 100k blocks works out to about two years. This was surprising to me, and I had expected the distribution to more strongly biased towards recent UTXOs. If you want to learn more about the age distribution I recommend checking out utxo-stats.com which presents this data in another more visually appealing way.
The next post will go more into database structure and caching details, but you can start thinking about some of the problem this poses now. In a database with asymmetric access patterns you can exploit things like recency to improve cache hit rates. This is most effective when there's a strong bias in the data, and the bias shown here exists but is fairly weak.
A Glimpse At The Future
Today you need to download and validate the full Bitcoin blockchain all the way from the genesis block in January 2009 to locally build the chainstate database. This is about 170 GB of data, and it's a fairly onerous task. This is a big problem because it's only going to get worse over time. Downloading 170 GB of data to build a 3 GB database isn't very efficient. A lot of people have correctly criticized Bitcoin by pointing out that this doesn't scale. A lot of Bitcoin and blockchain skeptics have also prematurely jumped to the conclusion that Bitcoin doesn't have a long term future due to these data storage requirements.
There's a really interesting area of active research about how to solve this problem. The basic idea is that if you could come up with a trustless way to bootstrap a copy of the chainstate database you wouldn't need to download and validate 170 GB of historical data. There are several different proposed solutions, and a number of Bitcoin developers are thinking about this problem and working on it right now. I'm not prescient and I don't have a crystal ball, but I think one of these is likely to make it into Bitcoin in the next two years (which takes into account the time it takes to build consensus around a BIP and actually deploy it).
The one that I think is most likely to make it into Bitcoin first is some kind of scheme built around Merkle sets. Bram Cohen (of BitTorrent fame) presented about this topic at the SF Bitcoin Developers meetup last year, and you can find a video of that on YouTube or transcribed notes here. This isn't the only idea, and there are a few really fascinating ideas using novel cryptographic primitives like [cryptographic accumulators](https://en.wikipedia.org/wiki/Accumulator_(cryptography)). One of the more well known proposals that you may have heard of is called MimbleWimble. However the Merkle set idea is probably the simplest proposal, and the one that's the most compatible with how Bitcoin actually works today. There are a lot of details that need to be ironed out, but the basic approach seems sound and has drawn a lot of interest. If you're interested in Bitcoin I definitely encourage you to read more about these ideas.
Regardless of what kind of scheme is used to bootstrap nodes in the future, Bitcoin will still need a chainstate database that operates essentially how it does today. There's no getting around the fact that you need to store accounting information in a database.