I've been busy for the last month or so working on a really interesting engineering problem: Making Bitcoin's chainstate database fast. The chainstate database is the core part of Bitcoin that tracks current/active balances and transactions; from a data perspective it's what makes Bitcoin "tick". This has been a really fascinating project because the chainstate database has very unusual access patterns, and a lot of the normal intuition for database optimization is ineffective. It's also been fun because I quickly got productive results: I have a GitHub PR up right now that makes blockchain sync times up to 25% faster. There's more work to be done though. My goal is to make Bitcoin the fastest and most efficient blockchain out there, at least from a database/storage perspective.
To measure my results I've been simulating IBD ("initial block download") times for nodes with slow disks. In other words, I'm simulating how long it takes to do a full sync of the Bitcoin blockchain for users with fast internet bandwidth and not very fast hard drives. This is a scenario that ends up bottle-necked on disk I/O as a result of building the chainstate database. The preliminary results are very promising. Here are the results from my current best branch compared to Bitcoin v0.16.0 (the current stable release):
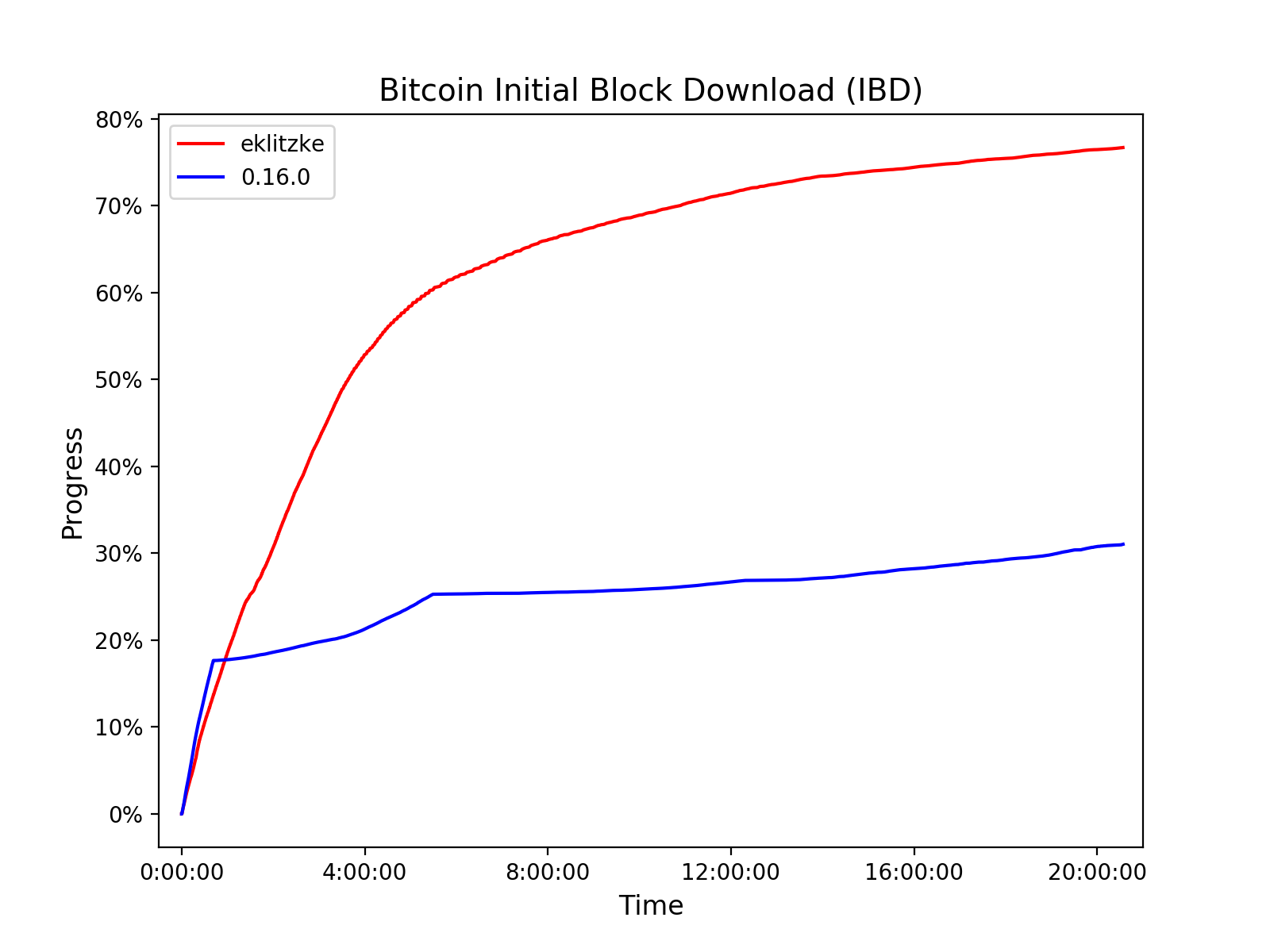
These are early measurements on code I have not yet submitted for review, and I'm testing on a configuration that's unusually bad for the current Bitcoin code. It's still exciting to see these kinds of numbers, and validates the work I've been doing. In the next post I'll explain the benchmarking methodology I used to create this graph, as well as details about what information is stored in the chainstate database.
The chainstate database itself is implemented in Bitcoin using LevelDB as the storage backend. Most of my work in the last month has been reading the LevelDB source from top to bottom, experimenting with changes to LevelDB internals, and testing different caching and buffering strategies within Bitcoin. I'm pretty deep in the weeds at this point, and have a solid grasp of most aspects of LevelDB internals regarding data layout and caching. A lot of important information in these areas is either completely undocumented, or only exists as out of date notes other people have written online. The result is that there's a lot of misinformation about LevelDB, and many projects (Bitcoin just being one of them) are leaving a lot of important optimizations on the table.
My primary goal in this series of blog posts is to document the darker corners of LevelDB, and explain the changes I'm making to the Bitcoin source code as a result of these discoveries. There's a lot of information locked up in my head that other people should know about. I want to keep a record of what I've found and how I've been testing different hypotheses.
Future articles will include the following:
- Part 1: Background on how Bitcoin uses LevelDB, details about what's
stored in the chainstate database, and why I think optimizing the chainstate
database is so important. I'll also explain how the mysterious
dbcacheconfiguration option works. - Part 2: Overview of how data is organized in LevelDB, and an overview of the read and write paths in LevelDB.
- Part 3: An explanation of how I'm approaching profiling this problem. This is more interesting than it sounds: I've patched Bitcoin to include SystemTap probes, and this has let me tackle the profiling problem in a very sophisticated way.
- Part 4: A look at Bitcoin PR #12495, a change I've made that can make initial sync times for new Bitcoin nodes as much as 25% faster.
- Part 5: Review of LevelDB read caches; changes I plan to make to Bitcoin in response to this; and a small improvement I plan to submit upstream to LevelDB to optimize the fast path even further.
- Part 6: A detailed look at the write buffer, and how to optimize write throughput. This is the part of Bitcoin that will have the most significant diff from the current code, and is the one I anticipate will have the biggest performance impact.
- Part 7+: Future directions for how Bitcoin uses LevelDB and whatever else I missed along the way. This will explore some of the more ambitious and long term changes I want to make.
I think this will be an interesting series of blog posts. Some of these will be somewhat short and some will be longer, but I think most of them will have interesting graphs and code examples. Stay tuned, and feel free to reach out to me over email if you want to discuss any of these topics in more detail.