When I first started learning modern C++ one of the things I found curious was
the widespread usage of pre-increment operators in for loops. For example, in
many other curly-brace languages the idiomatic way to write a for loop might
look something like:
// Note that i++ post-increments the loop variable
for (int i = 0; i < LEN; i++) {
// loop body here...
}
Whereas in C++, especially in loops using STL iterators, it's more common to use a pre-increment operator, e.g.:
// Note that ++it pre-increments the loop variable
for (auto it = foo.begin(); it != foo.end(); ++it) {
// loop body here...
}
If you search online for this topic you'll find a lot of Stack Overflow posts giving anecdotes claiming that the pre-increment form is faster. When I looked into this further I found some that linked to Gavin Baker's 2008 blog post STL Iterators and Performance, which explains why pre-incrementing STL iterators is faster, including some benchmarks demonstrating that using a pre-increment operator is up to 2x faster than post-incrementing. I will summarize the reasoning here, but Gavin's blog post is well written and covers some of the details more thoroughly, so I encourage you to take a look at his post if you want more details.
The Argument For Pre-Incrementing STL Iterators
The pre-increment and post-increment operators have different function signatures:
// Pre-increment, called for ++t
T& operator++();
// Post-increment, called for t++
const T operator++(int);
Note that the int parameter for the post-increment operator is actually a
dummy parameter, essentially a hack so the C++ type system can select which
operator++ implementation to use. In the pre-increment case the operator
should return a mutable reference to *this, and in the post-increment case the
operator should return a copy of the iterator's value from before the increment
was applied.
In practice, if we're writing a custom iterator type named Iter that might
look something like this:
// Pre-increment operator, returns a *mutable reference* to this.
Iter& operator++() {
// Logic to advance iterator here...
return *this;
}
// Post-increment operator for Iter, returns a *copy* of previous this value.
const Iter operator++(int) {
Iter copy = *this;
// Logic to advance iterator here...
return copy;
}
The post-increment operator has to perform an extra copy compared to the pre-increment operator. Gavin Baker's 2008 blog post shows that at least in the micro-benchmarks he ran it iss possible to observe overhead from the extra copy.
Is This Argument Still Relevant?
I was somewhat skeptical that the above argument is actually still valid nowadays, especially with modern compilers. I wanted to see if I could reproduce the overhead demonstrated by Gavin, especially since his original post is 13 years old now and a lot has changed in the C++ world since that post was originally written. I was skeptical primarily for two reasons:
- As far as I know all of the main STL implementations (GCC's
libstdc++, Clang'slibc++, and the MSVC implementation) implement iterators for STL containers as classes that have a single pointer data member variable. For example, an iterator for astd::vectoris actually implemented as a single pointer to the data offset in the underlying vector, and an iterator for astd::mapwould be a pointer to a node in a balanced tree. Since these iterators contain a single pointer value they will fit in a single 64-bit register, so copying these types is as cheap as can be (literally a singlemovinstruction). - More importantly: modern C++ compilers are extremely aggressive at inlining
and optimizing inlined code. An inlining compiler can see that the copy and
returned in the post-increment
operator++is completely unused, and therefore (in theory) can elide the copy entirely.
The original blog post includes a broken Github
link so I wasn't able to just run the
same code the original author used. However, I wrote my own micro-benchmarks
using Google's benchmark library. The
micro-benchmarks populate some different STL and
Abseil containers and measure how long
it takes to iterate over all the elements in the container. I disabled CPU
frequency scaling for all these benchmarks using sudo cpupower frequency-set --governor performance, which is the mode that benchmark recommends running in.
The full source code can be found
here and
built using
this Bazel
BUILD file. If you don't have a way to easily build Bazel C++ code you should be
able to remove the Abseil stuff from iterperf.cc and just link against the
benchmark library using these installation
instructions. I compiled this
code using Clang/libcxx 11.0.1 at optimization level -O3 with LTO enabled. The
basic idea in the code is I populate a vector or map data structure of unsigned
integers using std::iota and then sum them. The actual code I wrote is
somewhat macro heavy, but this is what something like the pre-increment
std::vector benchmark looks like after macro expansion:
static void BM_PreIncrementVector(benchmark::State& state) {
for (auto _ : state) {
unsigned sum = 0;
for (auto it = vec.begin(); it != vec.end(); ++it) {
benchmark::DoNotOptimize(sum += *it);
}
}
}
BENCHMARK(BM_PreIncrementVector)
The basic idea is to traverse the entire data structure and sum the values in
it, using either the pre-increment ++it or the post-increment it++ syntax in
the for loop. The benchmark::DoNotOptimize() call ensures that Clang doesn't
optimize away the loop entirely. Also note that there isn't any risk of
undefined behavior (e.g. if the sum overflowed) because all of the numeric types
in the program are unsigned. The benchmarks measure only the time to iterate the
containers (and sum their contents), time taken to construct the containers is
not counted.
To make these graphs interesting I made sure to put enough data into the
containers so that the data doesn't fit entirely in the CPU caches. The
containers in this benchmark contain 10 million unsigned 32-bit numbers (or
pairs or numbers for the associate containers). My computer has cache sizes of
32 KiB L1 Data, 256 KiB L2, and 8192 KiB L3, so the data set exceeds the L3
cache size by a fair amount, even for std::vector.
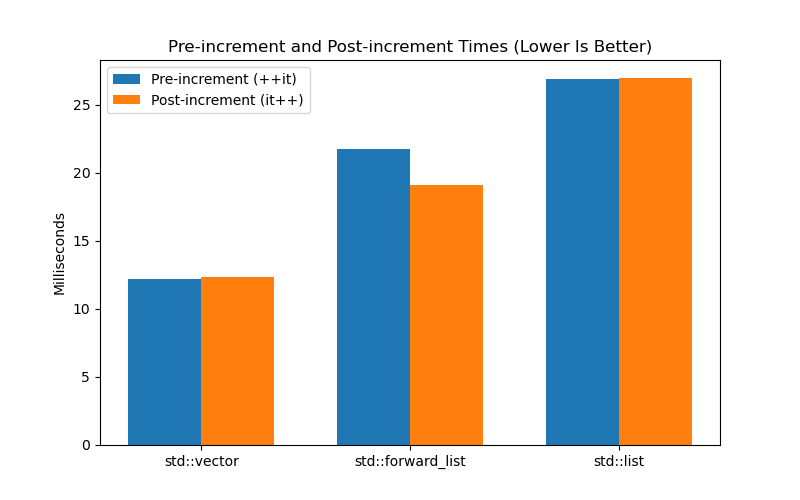
To keep the labels readable I've split the benchmark results into two graphs.
std::vector, std::forward_list, and std::list. As
I anticipated, and contrary to the measurements from Gavin's blog post, there is
no significant difference between pre-increment and post-increment times for
these containers:
The second graph shows times for the associative containers std::map,
std::unordered_map, absl::node_hash_map, and absl::flat_hash_map. This one
is similar in that there is no significant difference in run times for
pre-increment and post-increment:
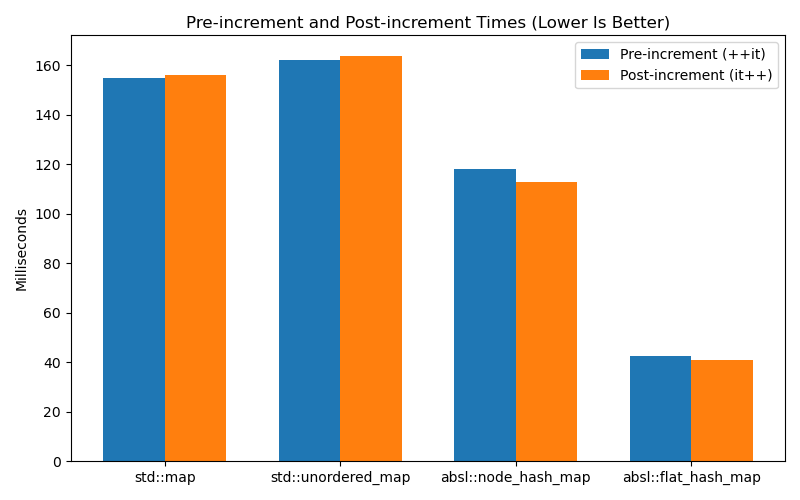
I ran this benchmark suite a few times and the exact times I get vary a bit from
run to run, but there is never any consistent difference in one version of
iterator access being faster than the other for any container types. I think the
way these graphs show the effects of cache locality is very interesting, and the
numbers for the Abseil map types really shows how much of an improvement you can
get over std::unordered_map.
Conclusions
Compilers have advanced since 2008, and if you're using a modern compiler and
compiling your code at a high optimization level, you probably won't observe any
performance speedup by using pre-increment operations on iterator types,
especially not for STL containers. Well written libraries should be including
the iterator definitions in header files, so compiling at -O2 or -O3 should
be sufficient to get good inlining (i.e. in most cases you shouldn't need to
have LTO enabled). It's possible to imagine some really pathological examples
where the inlining feature of the compiler would handle the two operators
differently, but that seems kind of far fetched in practice.
If you're working in a codebase that already uses the pre-increment ++it
syntax you should probably keep using that for consistency reasons. I've also
seen codebases where the pre-increment syntax is used for iterator types, and
the post-increment syntax is used for scalar types (e.g. int or size_t), and
again if that's the case you should probably maintain the convention for
consistency. But in general I wouldn't expect the choice of pre-increment or
post-increment to have an impact either way on how your program performs.
The above analysis is for optimized code only: in unoptimized code anything is possible, and I could imagine a case where pre-increment operators would be faster than post-increment operators when compiling at low optimization levels. But even in this case, the vast majority of loops in real-world programs are dominated by time spent in the loop body, not in the looping control structure itself. So in general my advice would be to not worry about this issue.